
Machine learning (ML) is a rapidly growing field of artificial intelligence that has the potential to revolutionize digital marketing. ML algorithms can analyze large amounts of data to identify patterns and trends that would be difficult or impossible to find manually. This information can then be used to create more targeted and effective marketing campaigns.
In this blog post, we will discuss some of the ways that ML is already being used to improve digital marketing, and how it is likely to be used in the future. We will also provide some tips for using ML in your own marketing campaigns.
By using tools like these, computer programmers and software engineers allow computers to evaluate data and solve issues; in other words, they build artificial intelligence systems.
- machine learning
- deep learning
- neural networks
- computer vision
- natural language processing
Table of Contents
What is ML?
According to its definition, ML is the application of technology to teach machines to carry out a variety of tasks, including recommendations, guesses, and predictions, based on previous experience or historical data.
Machine learning trains computers using projected data and historical experience to act like human beings.
The following are the three main facets of machine learning:
- Task: The primary issue that interests us is called a task. This task/problem may have something to do with estimations, recommendations, forecasts, etc.
- Experience: This is the ability to estimate and solve tasks in the future by drawing on data from the past.
- Performance: A machine’s ability to tackle a machine learning job or problem and produce the best result possible is referred to as performance. Performance, however, varies according to the nature of machine learning issues.
Techniques in ML
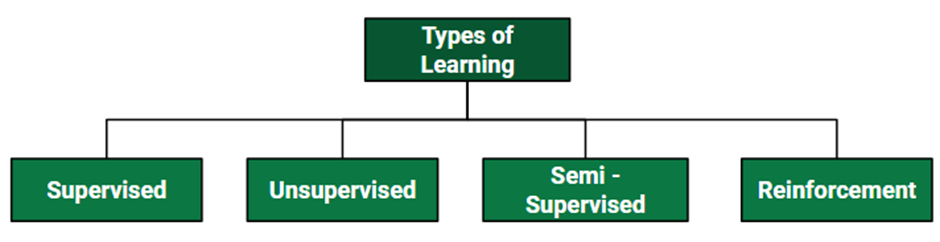
Machine Learning techniques are divided mainly into the following 4 categories:
1. Supervised Learning
Supervised learning is applicable when a machine has sample data, i.e., input as well as output data with correct labels. Correct labels are used to check the correctness of the model using some labels and tags. Supervised learning technique helps us to predict future events with the help of past experience and labeled examples. Initially, it analyses the known training dataset, and later it introduces an inferred function that makes predictions about output values. Further, it also predicts errors during this entire learning process and also corrects those errors through algorithms.
Example: Let’s assume we have a set of images tagged as ”dog”. A ML algorithm is trained with these dog images so it can easily distinguish whether an image is a dog or not.
2. Unsupervised Learning
In unsupervised learning, a machine is trained with some input samples or labels only, while output is not known. The training information is neither classified nor labeled; hence, a machine may not always provide correct output compared to supervised learning.
Although Unsupervised learning is less common in practical business settings, it helps in exploring the data and can draw inferences from datasets to describe hidden structures from unlabeled data.
Example: Let’s assume a machine is trained with some set of documents having different categories (Type A, B, and C), and we have to organize them into appropriate groups. Because the machine is provided only with input samples or without output, so, it can organize these datasets into type A, type B, and type C categories, but it is not necessary whether it is organized correctly or not.
3. Reinforcement Learning
Reinforcement Learning is a feedback-based ML technique. In such type of learning, agents (computer programs) need to explore the environment, perform actions, and on the basis of their actions, they get rewards as feedback. For each good action, they get a positive reward, and for each bad action, they get a negative reward. The goal of a Reinforcement learning agent is to maximize the positive rewards. Since there is no labeled data, the agent is bound to learn by its experience only.
4. Semi-supervised Learning
Semi-supervised learning is an intermediate technique of both supervised and unsupervised learning. It performs actions on datasets having few labels as well as unlabeled data. However, it generally contains unlabeled data. Hence, it also reduces the cost of the machine learning model as labels are costly, but for corporate purposes, it may have few labels. Further, it also increases the accuracy and performance of the machine learning model.
Semi-supervised learning helps data scientists to overcome the drawbacks of supervised and unsupervised learning. Speech analysis, web content classification, protein sequence classification, text document classifiers, etc., are some important applications of Semi-supervised learning.
Applications of ML
Machine Learning is widely being used in approximately every sector, including healthcare, marketing, finance, infrastructure, automation, etc. There are some important real-world examples of machine learning, which are as follows:

Healthcare and Medical Diagnosis:
ML is used in healthcare industries that help in generating neural networks. These self-learning neural networks help specialists for providing quality treatment by analyzing external data on a patient’s condition, X-rays, CT scans, various tests, and screenings. Other than treatment, machine learning is also helpful for cases like automatic billing, clinical decision supports, and development of clinical care guidelines, etc.
Self-driving cars:
This is one of the most exciting applications of machine learning in today’s world. It plays a vital role in developing self-driving cars. Various automobile companies like Tesla, Tata, etc., are continuously working for the development of self-driving cars. It also becomes possible by the machine learning method (supervised learning), in which a machine is trained to detect people and objects while driving.
Speech Recognition:
Speech Recognition is one of the most popular applications of machine learning. Nowadays, almost every mobile application comes with a voice search facility. This ”Search By Voice” facility is also a part of speech recognition. In this method, voice instructions are converted into text, which is known as Speech to text” or “Computer speech recognition.
Google assistant, SIRI, Alexa, Cortana, etc., are some famous applications of speech recognition.
Traffic Prediction:
Machine Learning also helps us to find the shortest route to reach our destination by using Google Maps. It also helps us in predicting traffic conditions, whether it is cleared or congested, through the real-time location of the Google Maps app and sensor.
Image Recognition:
Image recognition is also an important application of machine learning for identifying objects, persons, places, etc. Face detection and auto friend tagging suggestion is the most famous application of image recognition used by Facebook, Instagram, etc. Whenever we upload photos with our Facebook friends, it automatically suggests their names through image recognition technology.
Product Recommendations:
Machine Learning is widely used in business industries for the marketing of various products. Almost all big and small companies like Amazon, Alibaba, Walmart, Netflix, etc., are using machine learning techniques for product recommendations to their users. Whenever we search for any products on their websites, we automatically get started with lots of advertisements for similar products. This is also possible by Machine Learning algorithms that learn users’ interests and, based on past data, suggest products to the user.
Virtual Assistant:
A virtual personal assistant is also one of the most popular applications of machine learning. First, it records out voice and sends to cloud-based server then decode it with the help of machine learning algorithms. All big companies like Amazon, Google, etc., are using these features for playing music, calling someone, opening an app and searching data on the internet, etc.
Email Spam and Malware Filtering:
Machine Learning also helps us to filter various Emails received on our mailbox according to their category, such as important, normal, and spam. It is possible by ML algorithms such as Multi-Layer Perceptron, Decision tree, and Naïve Bayes classifier.
Marketing:
Machine learning helps marketers to create various hypotheses, testing, evaluation, and analyze datasets. It helps us to quickly make predictions based on the concept of big data. It is also helpful for stock marketing as most of the trading is done through bots and based on calculations from machine learning algorithms. Various Deep Learning Neural network helps to build trading models such as Convolutional Neural Network, Recurrent Neural Network, Long-short term memory, etc.
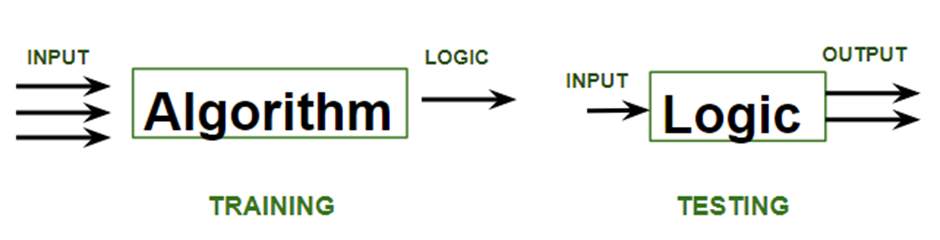
Supervised Machine Learning
Supervised learning is a machine learning technique that is widely used in various fields such as finance, healthcare, marketing, and more. It is a form of machine learning in which the algorithm is trained on labeled data to make predictions or decisions based on the data inputs.In supervised learning, the algorithm learns a mapping between the input and output data. This mapping is learned from a labeled dataset, which consists of pairs of input and output data. The algorithm tries to learn the relationship between the input and output data so that it can make accurate predictions on new, unseen data.
Let us discuss what learning for a machine is as shown below media as follows:
Types of Supervised Learning Algorithm
- Decision Trees
- Support Vector Machines
- Random Forests
- Naive Bayes
SVM (Support Vector Machine) Algorithm

SVM or Support Vector Machine is a linear model for classification and regression problems. It can solve linear and non-linear problems and work well for many practical problems. The idea of SVM is simple: The algorithm creates a line or a hyperplane which separates the data into classes.
At first approximation what SVMs do is to find a separating line(or hyperplane) between data of two classes. SVM is an algorithm that takes the data as an input and outputs a line that separates those classes if possible.
Lets begin with a problem. Suppose you have a dataset as shown below and you need to classify the red rectangles from the blue ellipses(let’s say positives from the negatives). So your task is to find an ideal line that separates this dataset in two classes (say red and blue).

Let’s take some probable candidates and figure it out ourselves.
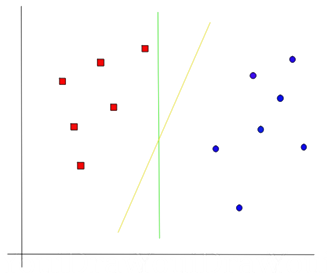
We have two candidates here, the green colored line and the yellow colored line. Which line according to you best separates the data?
If you selected the yellow line then congrats, because thats the line we are looking for. It’s visually quite intuitive in this case that the yellow line classifies better. But, we need something concrete to fix our line.
The green line in the image above is quite close to the red class. Though it classifies the current datasets it is not a generalized line and in machine learning our goal is to get a more generalized separator.
SVM’s way to find the best line
According to the SVM algorithm we find the points closest to the line from both the classes.These points are called support vectors. Now, we compute the distance between the line and the support vectors. This distance is called the margin. Our goal is to maximize the margin. The hyperplane for which the margin is maximum is the optimal hyperplane.
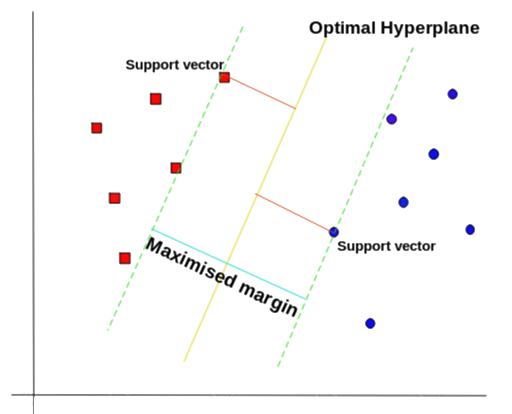
Thus SVM tries to make a decision boundary in such a way that the separation between the two classes(that street) is as wide as possible.
Unsupervised Learning
In this machine learning approach, algorithms analyze unlabeled data without predefined output labels. The objective is to discover patterns, relationships, or structures within the data. Unlike supervised learning, unsupervised learning algorithms work independently to uncover hidden insights and group similar data points together. Common unsupervised learning techniques include clustering algorithms like:
- K-means
- Hierarchical clustering
- Dimensionality Reduction Methods like PCA and t-SNE
K-Means Clustering Algorithm
K-Means Clustering is an Unsupervised Learning algorithm, which groups the unlabeled dataset into different clusters. Here K defines the number of pre-defined clusters that need to be created in the process, as if K=2, there will be two clusters, and for K=3, there will be three clusters, and so on.
It is a centroid-based algorithm, where each cluster is associated with a centroid. The main aim of this algorithm is to minimize the sum of distances between the data point and their corresponding clusters.
The algorithm takes the unlabeled dataset as input, divides the dataset into k-number of clusters, and repeats the process until it does not find the best clusters. The value of k should be predetermined in this algorithm.
The k-means clustering algorithm mainly performs two tasks:
- Determines the best value for K center points or centroids by an iterative process.
- Assigns each data point to its closest k-center. Those data points which are near to the particular k-center, create a cluster.
The below diagram explains the working of the K-means Clustering Algorithm:
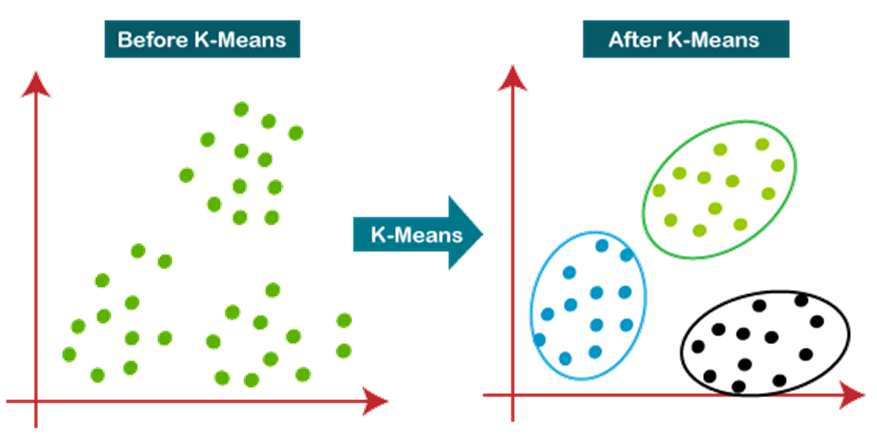
How does the K-Means Algorithm Work?
The working of the K-Means algorithm is explained in the below steps:
Step-1: Select the number K to decide the number of clusters.
Step-2: Select random K points or centroids. (It can be other from the input dataset).
Step-3: Assign each data point to their closest centroid, which will form the predefined K clusters.
Step-4: Calculate the variance and place a new centroid of each cluster.
Step-5: Repeat the third steps, which means reassign each datapoint to the new closest centroid of each cluster.
Step-6: If any reassignment occurs, then go to step-4 else go to FINISH.
Step-7: The model is ready.
Let’s understand the above steps by considering the visual plots:
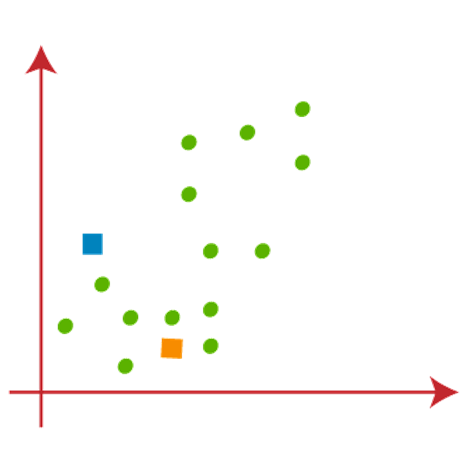
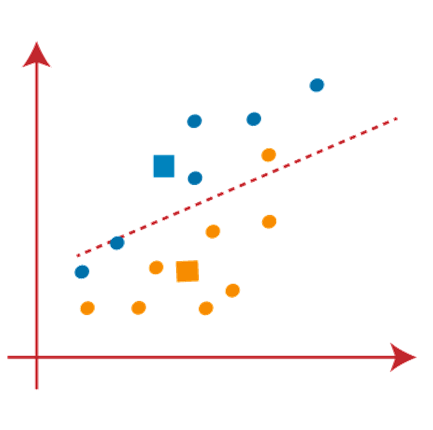
Suppose we have two variables M1 and M2. The x-y axis scatter plot of these two variables is given below:
- Let’s take number k of clusters, i.e., K=2, to identify the dataset and to put them into different clusters. It means here we will try to group these datasets into two different clusters.
- We need to choose some random k points or centroid to form the cluster. These points can be either the points from the dataset or any other point. So, here we are selecting the below two points as k points, which are not the part of our dataset. Consider the below image:
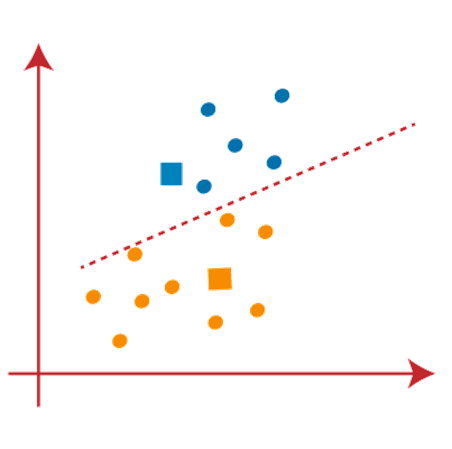
Now we will assign each data point of the scatter plot to its closest K-point or centroid. We will compute it by applying some mathematics that we have studied to calculate the distance between two points. So, we will draw a median between both the centroids. Consider the below image:
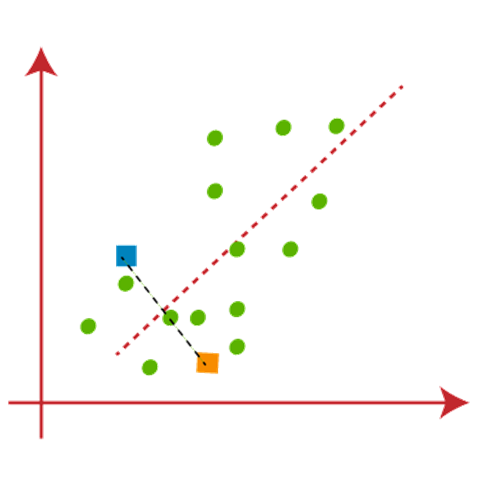
From the above image, it is clear that points left side of the line is near to the K1 or blue centroid, and points to the right of the line are close to the yellow centroid. Let’s color them as blue and yellow for clear visualization.
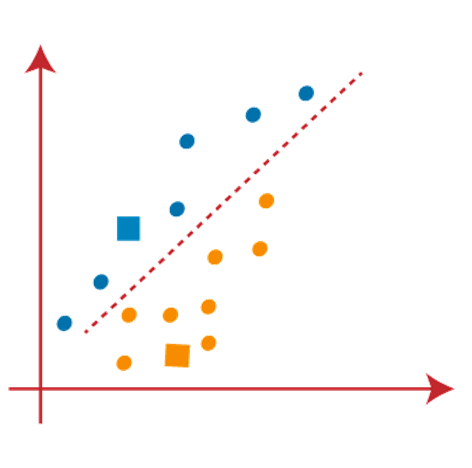
As we need to find the closest cluster, so we will repeat the process by choosing a new centroid. To choose the new centroids, we will compute the center of gravity of these centroids, and will find new centroids as below:
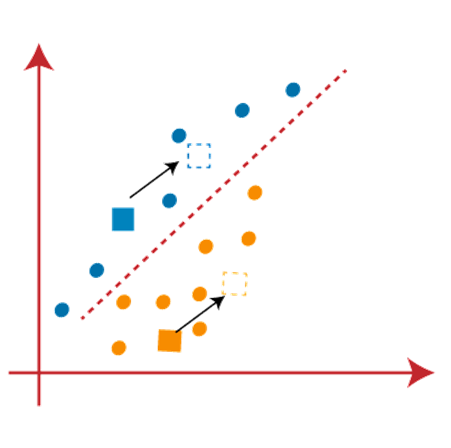
Next, we will reassign each datapoint to the new centroid. For this, we will repeat the same process of finding a median line. The median will be like below image:
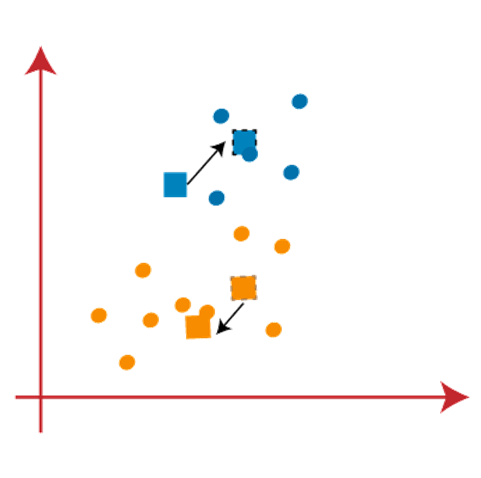
From the above image, we can see, one yellow point is on the left side of the line, and two blue points are right to the line. So, these three points will be assigned to new centroids.
As reassignment has taken place, so we will again go to the step-4, which is finding new centroids or K-points. We will repeat the process by finding the center of gravity of centroids, so the new centroids will be as shown in the below image:
As we got the new centroids so again will draw the median line and reassign the data points. So, the image will be:
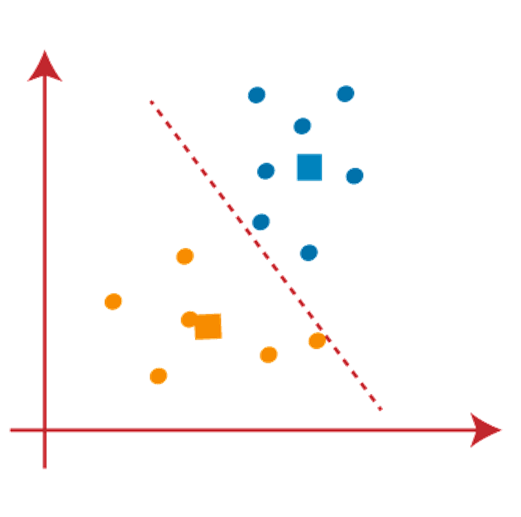
We can see in the above image; there are no dissimilar data points on either side of the line, which means our model is formed. Consider the below image:
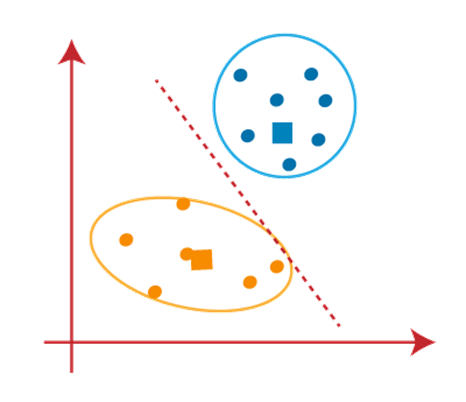
As our model is ready, so we can now remove the assumed centroids, and the two final clusters will be as shown in the below image:
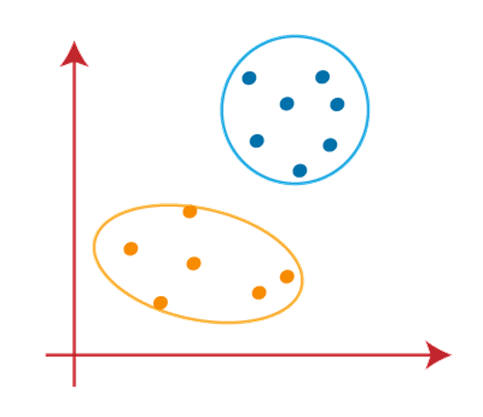
Principal Component Analysis
Principal Component Analysis (PCA) is an unsupervised linear transformation technique that is widely used across different fields, most prominently for feature extraction and dimensionality reduction.
PCA aims to find the directions of maximum variance in high-dimensional data and projects it onto a new subspace with equal or fewer dimensions than the original one.
In the preceding figure, x1 and x2 are the original feature axes, and PC1 and PC2 are the principal components.
If we use PCA for dimensionality reduction, we construct a d x k–dimensional transformation matrix W that allows us to map a sample vector x onto a new k–dimensional feature subspace that has fewer dimensions than the original d–dimensional feature space:
Before looking at the PCA algorithm for dimensionality reduction in more detail, let’s summarize the approach in a few simple steps:
- Standardize the d-dimensional dataset.
- Construct the covariance matrix.
- Decompose the covariance matrix into its eigenvectors and eigenvalues.
- Sort the eigenvalues by decreasing order to rank the corresponding eigenvectors.
- Select k eigenvectors which correspond to the k largest eigenvalues, where k is the dimensionality of the new feature subspace (k ≤ d).
- Construct a projection matrix W from the “top” k eigenvectors.
- Transform the d-dimensional input dataset X using the projection matrix W to obtain the new k-dimensional feature subspace.
AutoML | Automated
AutoML is a way to automate the time-consuming and iterative tasks involved in the machine learning model development process. It provides various methods to make machine learning available for people with limited knowledge of Machine Learning. It aims to reduce the need for skilled people to build the ML model. It also helps to improve efficiency and to accelerate the research on Machine learning.
To better understand automated machine learning, we must know the life cycle of a data science or ML project. A typical lifecycle of a data science project contains the following phases:
- Data Cleaning
- Feature Selection/Feature Engineering
- Model Selection
- Parameter Optimization
- Model Validation.
Despite advancements in technology, these processes still require manual effort, making them time-consuming and demanding for non-experts. The rapid growth of ML applications has generated a demand for automating these processes, enabling easier usage without expert knowledge. AutoML emerged to automate the entire process from data cleaning to parameter optimization, saving time and delivering excellent performance.
How does AutoML Work?
Per our problem or given task. It performs by following the two basic concepts:
- Neural Architecture Search: It helps in automating the design of neural networks. It enables AutoML models to discover new architectures as per the problem requirement.
- Transfer Learning: With the help of transfer learning, previously trained models can apply their logic to new datasets that they have learned. It enables AutoML models to apply available architectures to the new problems.
Pros
- Performance: AutoML performs most of the steps automatically and gives a great performance.
- Efficiency: It provides good efficiency by speeding up the machine learning process and by reducing the training time required to train the models.
- Cost Savings: As it saves time and the learning process of machine learning models, hence also reduces the cost of developing an ML model.
- Accessibility: AutoML enables those with little background in the area to use the potential of ML models by making machine learning accessible to them.
- Democratization of ML: AutoML democratises machine learning by making it easier for anybody to use, hence maximising its advantages.
Cons
- Lack of Human Expertise: AutoML can be considered as a substitute for human knowledge, but human oversight, interpretation, and decision-making are still required.
- Limited Customization: Limited customization possibilities on some AutoML systems may make it difficult to fine-tune models to meet particular needs.
- Dependency on Data Quality: The accuracy and relevancy of the supplied data are crucial to AutoML. The quality and performance of the generated models may be impacted by biassed, noisy, or missing data.
- Complexity of Implementation: Even while AutoML makes many parts of machine learning simpler, incorporating AutoML frameworks into current processes may need more time and technical know-how.
- Lack of Platform Maturity: Since AutoML is still a relatively young and developing area, certain platforms could still be in the works and be in need of improvements.
Applications
AutoML shares common use cases with traditional machine learning. Some of these include:
- Image Recognition: AutoML is also used in image recognition for Facial Recognition.
- Risk Assessment: For banking, finance, and insurance, it can be used for Risk Assessment and management.
- Cybersecurity: In the cybersecurity field, it can be used for risk monitoring, assessment, and testing.
- Customer Support: Customer support where can be used for sentiment analysis in chatbots and to increase the efficiency of the customer support team.
- Malware & Spam: To detect malware and spam, AutoML can generate adaptive cyberthreats.
- Agriculture: In the Agriculture field, it can be used to accelerate the quality testing process.
- Marketing: In the Marketing field, AutoML is employed to predict analytics and improve engagement rates. Moreover, it can also be used to enhance the efficiency of behavioral marketing campaigns on social media.
- Entertainment: In the entertainment field, it can be used as the content selection engine.
- Retail: In Retail, AutoML can be used to improve profits and reduce the inventory carry.
Conclusion
ML is a powerful tool that can be used to improve digital marketing in a variety of ways. By using ML, you can personalize marketing messages, target ads more effectively, predict customer behavior, and optimize your content.
If you are interested in using ML in your own marketing campaigns, be sure to start with a clear goal in mind, collect the right data, use a variety of ML tools and strategies, and monitor your results.
About more detail on my site:
